Freedman's Paradox
Release Date: //1983
Country of Release:
Length:
MPAA:
Medium: Paradox
Genre:
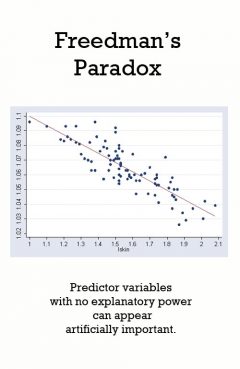
Release Message: It describes a problem in model selection where predictor variables with no explanatory power can appear artificially important. Authored by David A. Freedman.
Description: In statistical analysis, Freedman's paradox, named after David Freedman, describes a problem in model selection whereby predictor variables with no explanatory power can appear artificially important. Freedman demonstrated (through simulation and asymptotic calculation) that this is a common occurrence when the number of variables is similar to the number of data points. Recently, new information-theoretic estimators have been developed in an attempt to reduce this problem, in addition to the accompanying issue of model selection bias, whereby estimators of predictor variables that have a weak relationship with the response variable are biased.